El propósito del lanzamiento de ArcGIS Pro 3.2 es mejorar la experiencia de usuario y la productividad cuando se usan herramientas de Aprendizaje Profundo (Deep Learning) incluidas en la extensión de Image Analyst. Se han introducido nuevas experiencias para la creación de muestras de entrenamiento, el entrenamiento de modelos y la inferencia. Adicionalmente, se han mejorado significativamente las capacidades para el entrenamiento de modelos. En este artículo podrán encontrar un resumen de las nuevas capacidades de Deep Learning que se pueden encontrar en este lanzamiento:
- Creación de capas dinámicas para el etiquetado de muestras de entrenamiento
- Experiencia de usuario mejorada para el entrenamiento y la revisión de modelos de Deep Learning:
- Wizard para el entrenamiento de modelos de Deep Learning
- Panel de detalles del modelo de Deep Learning
- Mejoramiento de la experiencia de usuario para el entrenamiento de modelos de Deep Learning por medio de las herramientas de geoprocesamiento
- Mejoras en el rendimiento de los flujos de entrenamiento
- Data Augmentation para entrenamiento y validación
- Utilización de pesos para construir mejores modelos para imágenes multiespectrales
- Ajuste automático del tamaño del lote según la disponibilidad de la memoria GPU
- Soporte para conexiones a almacenamiento en la nube
- Múltiple GPU en una sola máquina para modelos seleccionados
- Mejoramiento en los tipos de modelos
- Mejor soporte de la inferencia en imágenes oblicuas
- Flujos de trabajo de documentación de principio a fin
Creación de capas dinámicas para el etiquetado de muestras de entrenamiento
En algunos casos se pueden encontrar con la necesidad de crear etiquetas en múltiples imágenes. Este flujo de trabajo está soportado por medio de la opción Image Collection. Sin embargo, anteriormente, solo se podía crear un conjunto de datos de mosaico primero, y luego usarlo como una colección de imágenes.
Ahora, no se tiene la necesidad de crear conjuntos de datos de mosaico. Cuando se abre la herramienta de Etiquetado de objetos para Deep Learning (Label Objects for Deep Learning), le preguntará si desea usar una capa existente o si quiere crear una capa nueva. Cuando se crea una nueva colección de imágenes, puede simplemente señalar a una carpeta donde se encuentren las imágenes, y la herramienta automáticamente creará una capa de colección de imágenes. Por lo tanto podrá hacer las tareas de etiquetado de modo fácil y rápido.
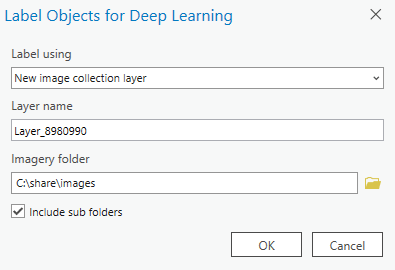
Capa dinámica para el etiquetado de muestras de entrenamiento.
Experiencia de usuario mejorada para el entrenamiento y la revisión de modelos de Deep Learning
El nuevo wizard para el Entrenamiento de modelos de Deep Learning y el panel de revisión de los modelos de Deep Learning se pueden encontrar en la pestaña de Imagery, debajo de las herramientas de Deep Learning. Adicionalmente, el panel de Etiquetado de objetos de Deep Learning también se encuentra en las herramientas de Deep Learning.
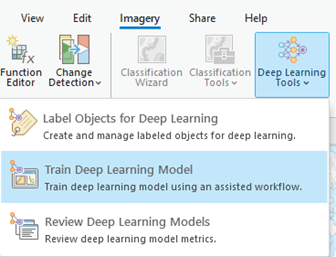
Herramientas de Deep Learning
Wizard para el Entrenamiento de modelos de Deep Learning
El wizard para el Entrenamiento de modelos de Deep Learning es un asistente para los flujos de trabajo que requieran los modelos de aprendizaje. Este wizard consiste en tres páginas: Preparación, Entrenamiento y Resultados.
En la pagina de Preparación (Get Started), encontrará específicamente cómo se debe entrenar el modelo por medio de dos opciones:
- Establecer los parámetros automáticamente: Esta opción permite que el software trate de identificar los diferentes modelos, tipos, parámetros y los hiperparámetros para construir el mejor modelo dentro de un tiempo definido.
- Especificar mis propios parámetros: con esta opción, se va a tener el control completo sobre las opciones del tipo de modelo, parámetros e hiperparámetros, dando control a todo el proceso de entrenamiento.
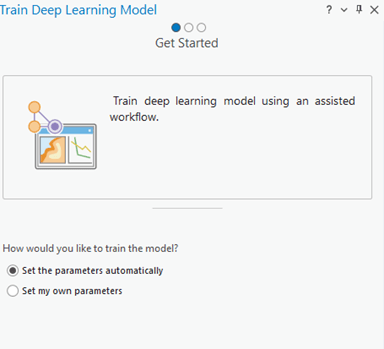
Wizard para el Entrenamiento de modelos de Deep Learning.
En la página Entrenar, se deben de configurar sus parámetros de entrada, salida y opcionales, y luego ejecutar la herramienta. Aquí puede ver el progreso de la herramienta mientras se ejecuta. Una vez que se completa el entrenamiento, la página de resultados muestra los detalles del modelo. También tiene la opción de compararlo con otros modelos.
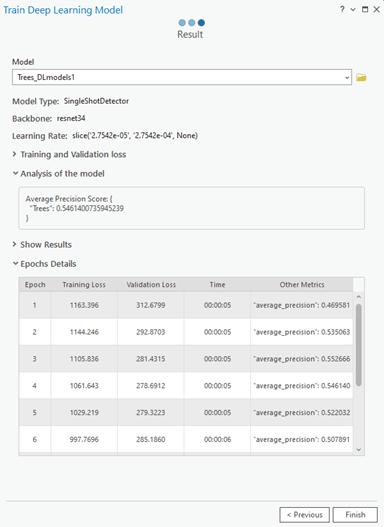
Asistente para entrenar modelos de Deep Learning: panel de resultados
Revisar el modelo de Deep Learning
Revisar un modelo proporciona información sobre su proceso de entrenamiento y su rendimiento potencial. En casos determinados, es posible que tenga varios modelos a mano para comparar. El panel Revisar modelo de Deep Learning es una interfaz de usuario adicional que le permite revisar los modelos existentes.
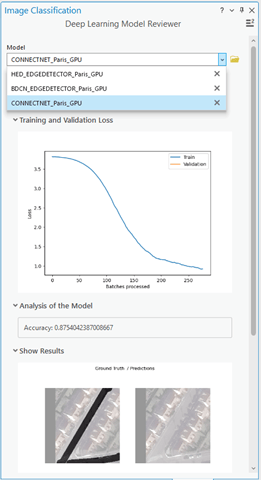
Panel Revisar modelo de Deep Learning
Experiencia de usuario mejorada de la herramienta de geoprocesamiento Entrenar modelo de Deep Learning
Esri ha realizado varias mejoras en la herramienta Entrenar modelo de Deep Learning, mejorando tanto su apariencia como su funcionalidad. La agrupación de varios parámetros se ha rediseñado para proporcionar una experiencia de usuario más intuitiva. Los parámetros ahora están organizados en dos grupos: Preparación de datos y Avanzado. Sin embargo, los parámetros más importantes que se modifican con frecuencia se encuentran en la parte superior de la herramienta.
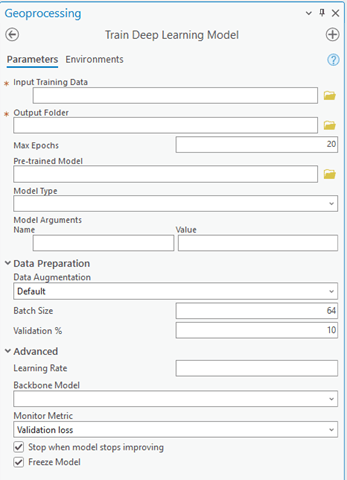
Experiencia de usuario mejorada de la herramienta de geoprocesamiento Entrenar modelo de Deep Learning
Mejoras de productividad para el entrenamiento.
Además de la mejora en la apariencia de las herramientas, también hay importantes mejoras de productividad:
- Data Augmentation
- Esquema de inicialización de pesos
- Ajuste automático del tamaño del lote de acuerdo a la GPU
- Soporte de conexiones de almacenamiento en la nube
- Soporte para múltiples GPU
- Tipos de modelos mejorados
Data Augmentation
Esta es una técnica para reducir el sobreajuste al entrenar un modelo. Implica aumentar artificialmente el tamaño de un conjunto de datos cambiando aleatoriamente propiedades como la rotación, el brillo, el recorte y más chips de imagen. La herramienta ahora ofrece la capacidad de realizar un aumento de datos definido por el usuario, tanto para datos de entrenamiento como de validación. Además, tiene un mayor control sobre cómo se aplica el aumento de datos.
Podrá elegir entre opciones como configuración predeterminada, sin aumento, personalización de métodos existentes o utilizar un archivo JSON que contiene muchos métodos de aumento de datos compatibles con transformaciones visuales.
En la imagen a continuación, mostramos algunos ejemplos de aumento de imágenes en un chip de imagen de marcador GCP.

Ejemplos de aumento de imagen en un chip de imagen de marcador GCP
Esquema de inicialización de peso
El esquema de inicialización de peso es un nuevo parámetro para construir mejores modelos para imágenes multiespectrales. Puede especificar el esquema en el que se inicializan los pesos para sus datos.
Ajuste automático del tamaño del lote según la disponibilidad de memoria de la GPU
Ahora la herramienta puede ajustar el tamaño del lote según la memoria GPU disponible de la máquina.
Soporte para conexiones de almacenamiento en la nube
Ahora también admite datos de entrenamiento de entrada y modelos de salida desde conexiones de almacenamiento en la nube.
Múltiples GPU en una sola máquina para tipos de modelos seleccionados
De forma predeterminada, la herramienta utiliza todas las GPU disponibles en la máquina para los siguientes tipos de modelos de uso común: ConnectNet, Clasificador de entidades, MaskRCNN, Multi Task Road, Extractor, Single Shot Detector, U-Net. Para utilizar una GPU específica, puede utilizar el entorno de ID de GPU.
Tipos de modelos mejorados
Ahora puede usar Super Resolución para conjuntos de datos multiespectrales. Hemos mejorado el soporte para MMSegmentation y MMDetection.
Mejor soporte para inferencias en imágenes oblicuas.
Las imágenes oblicuas o de vista de la calle tienen más detalles contextuales de los objetos en el suelo en comparación con las imágenes orto. Por lo tanto, es mejor realizar inferencias en Pixel Space y transformarlo en Map Space. Este flujo de trabajo es compatible con colecciones de imágenes (conjuntos de datos de mosaico) que contienen imágenes con información de marco y cámara. Tales colecciones de imágenes se crean utilizando la funcionalidad de mapeo orto en ArcGIS Pro o ArcGIS Drone2Map . Sin embargo, estas colecciones de imágenes contienen muchas imágenes superpuestas y es posible que no necesitemos inferir imágenes duplicadas. En Pro 3.2, hemos agregado un nuevo modo de procesamiento llamado Procesar solo elementos candidatos. Puede utilizar este nuevo modo de procesamiento para detectar objetos (o clasificar píxeles) solo en imágenes seleccionadas de la colección de imágenes.
La herramienta Computar mosaicos candidatos se puede utilizar para encontrar las imágenes candidatas que mejor representen el área del mosaico. La herramienta agrega una nueva columna llamada Candidatos. Cuando usa el modo de procesamiento Procesar solo elementos candidatos, solo se usan las imágenes identificadas en las columnas Candidatos.
¿Qué opina de estas mejoras? ¿Tiene algún caso de uso que pueda beneficiarse de estas nuevas funcionalidades? Comparta sus ideas para mejorar los flujos de trabajo de Aprendizaje Profundo en ArcGIS.
Este artículo originalmente apareció en la edición global del Blog de ArcGIS el 14 de noviembre de 2023.
comentarios
0